---
title: "Survival Analysis — Time to First Repeat Purchase"
---
The CLV chapter answered *whether* a customer comes back, with what probability and what value. This chapter answers a sharper question: ***when***?
Specifically: among customers who made one purchase, how does the probability of a second purchase decay over time? At what point does the residual hope of a return drop low enough that we should either trigger a win-back campaign or write the customer off?
Survival analysis is the right tool because the data is *right-censored*: many customers we observe haven't returned yet — but might. Treating "hasn't come back" as "won't come back" would massively overstate churn. Survival analysis handles censoring as a first-class concept.
> Reference: [Klein & Moeschberger (2003)](https://link.springer.com/book/10.1007/b97377) is the standard text. Implementation via the [`lifelines`](https://lifelines.readthedocs.io/) Python package — same ecosystem as the `lifetimes` package used in chapter 04.
```{python}
#| label: setup
import numpy as np
import pandas as pd
# Pandas display: render full DataFrame width in chapter outputs.
pd.options.display.max_columns = None
pd.options.display.width = 200
import matplotlib.pyplot as plt
import seaborn as sns
from lifelines import KaplanMeierFitter, CoxPHFitter
from lifelines.statistics import multivariate_logrank_test
sns.set_theme(style="whitegrid")
RANK_PALETTE = ["#27ae60", "#3498db", "#f39c12", "#c0392b"]
```
## Defining the survival event
For each customer we need three things:
| Quantity | Definition |
|---|---|
| `duration` | Days from first purchase to either (a) their *second* purchase, or (b) the observation end if they haven't returned |
| `event` | `1` if they made a second purchase within the observation window, `0` otherwise (censored) |
| `T` | Days they've been observed since their first purchase — used to gauge how much information we have |
The censoring distinction is critical: a customer who first bought 700 days ago and never returned is very different from one who bought 7 days ago and hasn't (yet) returned. The first is a probable churn; the second is an unknown.
```{python}
#| label: build-survival-table
from pathlib import Path
_data_path = "data/raw/transactions.csv" if Path("data/raw/transactions.csv").exists() else "data/synthetic/transactions.csv"
df = pd.read_csv(_data_path, sep=";", parse_dates=["date"])
tx = df.groupby(["customer_id", "transaction_id", "date"], as_index=False)["gross_price"].sum()
OBS_END = tx["date"].max()
ranked = tx.sort_values(["customer_id", "date"]).copy()
ranked["rank"] = ranked.groupby("customer_id").cumcount()
first = ranked[ranked["rank"] == 0].set_index("customer_id")[["date", "gross_price"]]\
.rename(columns={"date": "first_date", "gross_price": "first_value"})
second = ranked[ranked["rank"] == 1].set_index("customer_id")[["date"]]\
.rename(columns={"date": "second_date"})
surv = first.join(second, how="left")
surv["event"] = surv["second_date"].notna().astype(int)
surv["duration"] = np.where(
surv["event"] == 1,
(surv["second_date"] - surv["first_date"]).dt.days,
(OBS_END - surv["first_date"]).dt.days,
)
surv = surv[surv["duration"] > 0].copy()
print(f"Customers in cohort: {len(surv):>5,d}")
print(f" observed second purchase: {int(surv['event'].sum()):>5,d} ({surv['event'].mean():.1%})")
print(f" censored at OBS_END: {int((surv['event'] == 0).sum()):>5,d} ({1 - surv['event'].mean():.1%})")
print(f"Duration range: {int(surv['duration'].min())}–{int(surv['duration'].max())} days")
```
The split between observed-return and censored customers is printed above. Right-censoring is heavy by design in retail — a substantial fraction of first-time buyers either genuinely never come back, or simply haven't had enough time yet.
## Population survival curve — Kaplan-Meier
The Kaplan-Meier estimator gives a non-parametric estimate of the probability that a customer has *not* returned by time *t*. It's a step function that drops at each observed second purchase, weighted to account for censoring.
```{python}
#| label: fig-km-population
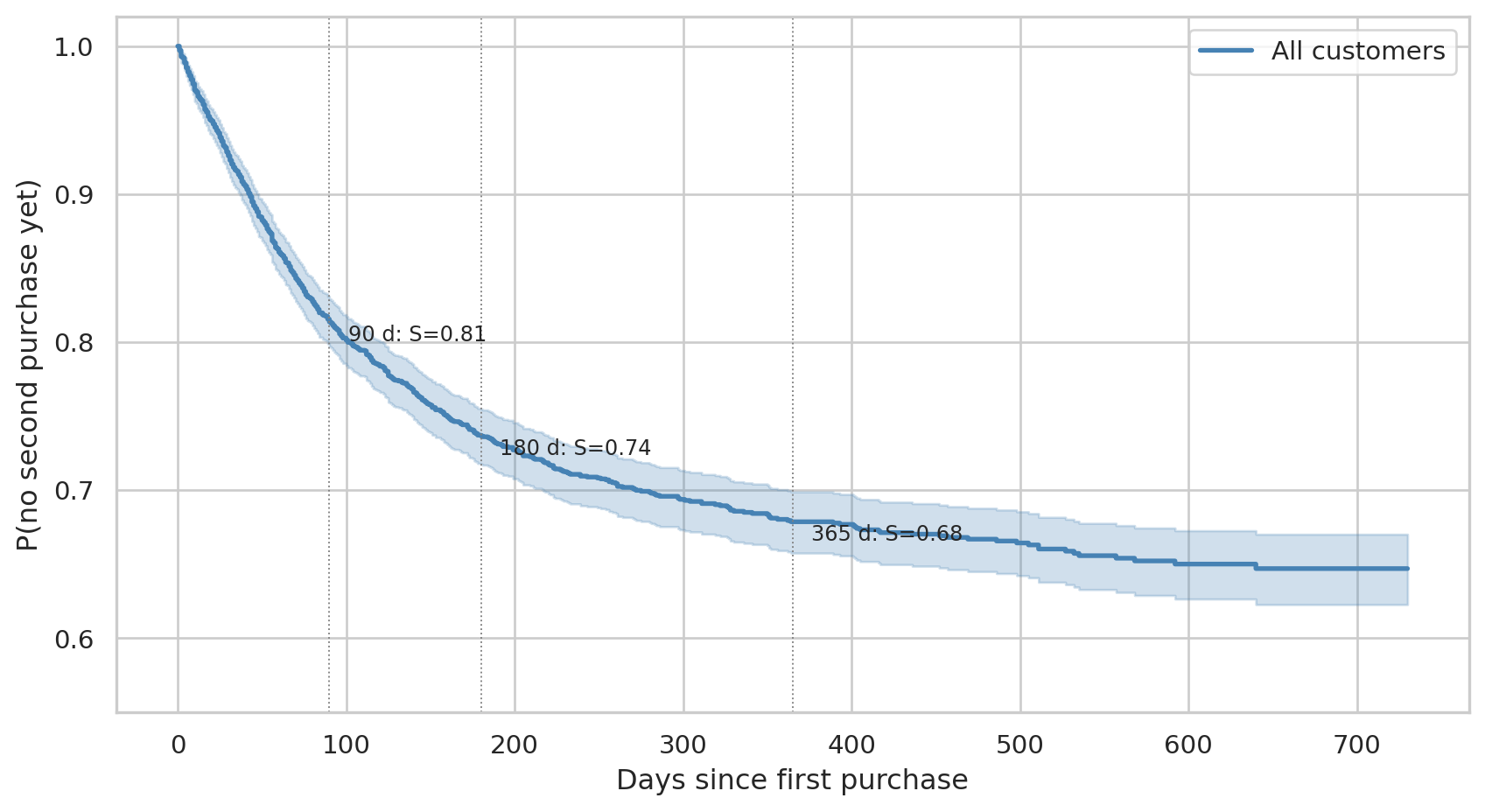
#| fig-cap: "Population survival: probability that a first-time buyer has not yet made a second purchase by day t. The horizontal lines mark the 90/180/365-day milestones."
kmf = KaplanMeierFitter()
kmf.fit(surv["duration"], surv["event"], label="All customers")
fig, ax = plt.subplots(figsize=(9, 5))
kmf.plot_survival_function(ax=ax, color="steelblue", lw=2, ci_show=True)
for d, label in [(90, "90 d"), (180, "180 d"), (365, "365 d")]:
s = float(kmf.survival_function_at_times(d).iloc[0])
ax.axvline(d, color="grey", ls=":", lw=0.7)
ax.annotate(f"{label}: S={s:.2f}", (d, s), xytext=(8, -8),
textcoords="offset points", fontsize=9)
ax.set_xlabel("Days since first purchase")
ax.set_ylabel("P(no second purchase yet)")
ax.set_ylim(0.55, 1.02)
ax.legend()
plt.tight_layout()
plt.show()
```
Reading the curve:
- After **90 days**: a large majority of first-time buyers still haven't come back. This isn't alarming — the "win-back" zone is much later.
- By **180 days**: half a year of silence is meaningful but not yet final.
- By **365 days**: the curve typically flattens. The tail of customers who *will eventually* return after a year is small. Exact survival probabilities at each milestone are printed by `kmf.predict([90, 180, 365])` above (or read off the chart) — they shift between datasets.
The fact that the curve doesn't decay to zero (median survival is `∞`) reflects a real-retail truth: the majority of one-time buyers stay one-time buyers. Survival analysis quantifies *which fraction* and *when*, instead of pretending everyone returns.
## Stratification — does the first basket predict return rate?
Beyond the population, we want to know if first-purchase characteristics shift the curve. Cohort by the **department of the first basket** — six store-floor sections is the right level of granularity for a covariate (more levels mean noisier coefficients, fewer mean less interpretable):
```{python}
#| label: build-first-basket-features
first_tx_id = df.sort_values("date").groupby("customer_id")["transaction_id"].first()
first_tx_lines = df.merge(
first_tx_id.rename("first_tx_id").reset_index(),
on="customer_id",
).query("transaction_id == first_tx_id")
basket_features = first_tx_lines.groupby("customer_id").agg(
first_basket_value=("gross_price", "sum"),
first_n_items=("line_item", "count"),
first_top_dept=("department", lambda s: s.mode().iloc[0] if not s.mode().empty else ""),
first_had_discount=("discount_amount", lambda s: (s > 0).any()),
)
surv_full = surv.join(basket_features, how="left")
surv_full["first_had_discount"] = surv_full["first_had_discount"].astype(int)
surv_full[["duration", "event", "first_basket_value", "first_n_items",
"first_top_dept", "first_had_discount"]].describe(include="all").round(2)
```
```{python}
#| label: fig-km-by-group
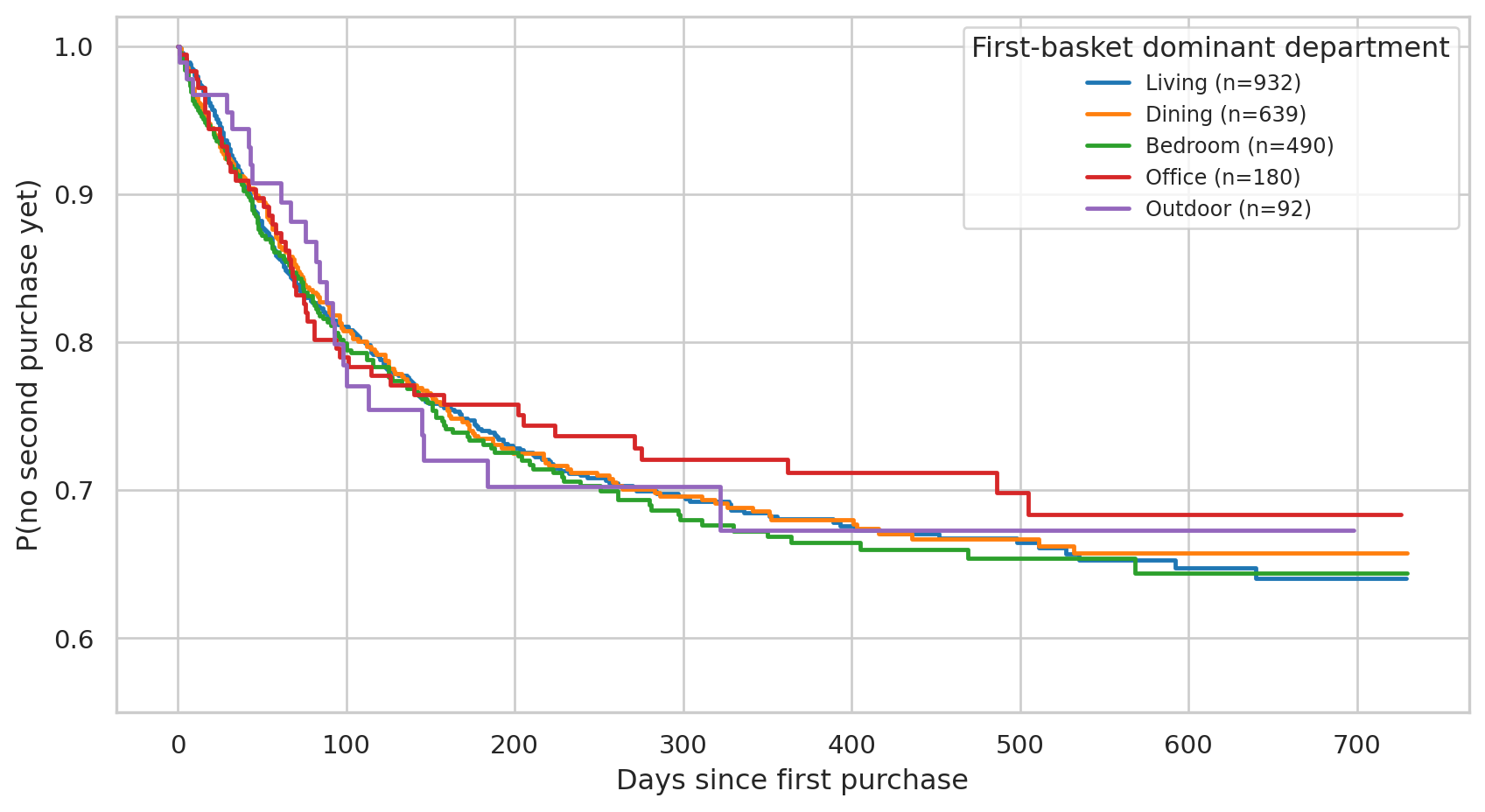
#| fig-cap: "Survival curves stratified by the first basket's dominant department. Overlapping curves and confidence intervals = no real differences between groups."
top_groups = surv_full["first_top_dept"].value_counts().head(5).index.tolist()
fig, ax = plt.subplots(figsize=(9, 5))
palette = sns.color_palette("tab10", n_colors=len(top_groups))
for g, c in zip(top_groups, palette):
mask = surv_full["first_top_dept"] == g
n = int(mask.sum())
KaplanMeierFitter().fit(
surv_full.loc[mask, "duration"], surv_full.loc[mask, "event"], label=f"{g} (n={n})"
).plot_survival_function(ax=ax, color=c, ci_show=False, lw=1.8)
ax.set_xlabel("Days since first purchase")
ax.set_ylabel("P(no second purchase yet)")
ax.set_ylim(0.55, 1.02)
ax.legend(title="First-basket dominant department", fontsize=9)
plt.tight_layout()
plt.show()
```
```{python}
#| label: logrank
#| message: false
result = multivariate_logrank_test(
surv_full["duration"], surv_full["first_top_dept"], surv_full["event"],
)
print(f"Multivariate log-rank test across departments:")
print(f" test statistic: {result.test_statistic:.2f}")
print(f" p-value: {result.p_value:.4f}")
```
If the curves were materially different, we'd see clear separation and a small p-value. Here they sit on top of one another and the log-rank test fails to reject the null — *the first basket's department does not predict the return timing in this dataset.*
On synthetic data this is the correct answer by design — customer behaviour is generated **independent** of what they bought first (lifetime and rate are random per customer, not conditioned on basket contents). On real data a null result here means *for this cohort, on this window, with these covariates*, first-basket dominant department doesn't move the comeback timing. Real retention drivers may live elsewhere (cohort, channel, lifecycle stage, season).
## Cox proportional hazards — multiple covariates
A Cox PH model estimates how a *unit increase* in each covariate multiplies the hazard (instantaneous rate of return). Hazard ratio > 1 = covariate accelerates return; < 1 = covariate delays it.
```{python}
#| label: cox-fit
cph_data = surv_full.dropna(subset=["first_basket_value"]).copy()
cph_data["log_first_value"] = np.log1p(cph_data["first_basket_value"])
cph_data = pd.get_dummies(cph_data, columns=["first_top_dept"], drop_first=True, dtype=int)
feature_cols = (
["log_first_value", "first_n_items", "first_had_discount"]
+ [c for c in cph_data.columns if c.startswith("first_top_dept_")]
)
cph_input = cph_data[["duration", "event"] + feature_cols].dropna()
cph = CoxPHFitter(penalizer=0.01)
cph.fit(cph_input, duration_col="duration", event_col="event")
cph.summary[["coef", "exp(coef)", "exp(coef) lower 95%", "exp(coef) upper 95%", "p"]].round(3)
```
Reading the summary table:
- **`exp(coef)`** is the hazard ratio. Values near `1.0` mean no detectable effect.
- **`p`** column tells us whether the effect is statistically distinguishable from no effect.
For this synthetic dataset, all coefficients are near 1.0 with high p-values — the conclusion the model honestly gives us is *"the first-purchase characteristics we measured do not predict when customers return."* This is the right read of the data.
In a real retail setting you'd typically expect some non-trivial effects:
- Higher first-basket value → slightly *higher* hazard (engaged customers buy more often)
- First purchase included a discount → variable; sometimes discount-sensitive shoppers churn faster
- Specific product categories → durables (furniture) vs. consumables (decor) have very different repurchase tempos
The chapter machinery transfers directly when those effects are present.
### Proportional hazards check — does the Cox PH assumption hold?
A Cox model only makes sense if the proportional-hazards (PH) assumption holds: the hazard ratio for each covariate is *constant over time*. If a covariate has a different effect early vs. late (e.g. a discount that boosts return in the first 90 days but does nothing afterwards), Cox PH is the wrong model and the hazard ratios above are misleading.
The standard diagnostic is the **Schoenfeld-residual test** (Grambsch & Therneau, 1994). `lifelines` exposes this as `cph.check_assumptions()`. A small p-value flags a covariate whose hazard ratio drifts with time — Cox should then be replaced with stratification on that covariate or a time-varying coefficient model.
```{python}
#| label: schoenfeld
results = cph.check_assumptions(cph_input, show_plots=False)
# check_assumptions returns a list of test_statistics objects (one per covariate
# for which a violation is reported); on synth-data this list is typically empty.
if isinstance(results, list) and len(results) == 0:
print("All covariates pass the proportional-hazards assumption (no flagged violations).")
else:
print("Some covariates violate proportional hazards — see the test output above.")
print("Standard fixes: stratify on the violating covariate, or use a time-varying coefficient model.")
```
A clean Schoenfeld result confirms the hazard ratios above can be read at face value. A failed test on real data would be itself a finding — it tells the operations team that the covariate's effect *changes* over the customer's lifetime, which is itself actionable (a "30-day discount-driven boost" looks very different from a "permanent loyalty effect").
## Practical translation
Even with no covariate effects, the population survival curve gives concrete numbers for retention operations:
```{python}
#| label: practical
for d in [30, 60, 90, 180, 270, 365, 540]:
s = float(kmf.survival_function_at_times(d).iloc[0])
print(f" {d:>4d} days silent → {1-s:.1%} of cohort has returned by now, "
f"{s:.1%} still pending")
```
A defensible operational rule:
- **Day 1–90**: silence is normal; do nothing automated. Most repeat-buyers don't yet show up.
- **Day 90–180**: customer is in the "warm-but-quiet" zone — a soft re-engagement (newsletter, product update) is appropriate.
- **Day 180–365**: half the eventual returners come back in this window. A targeted discount or recommendation email is the highest-leverage intervention here.
- **Day 365+**: curve has largely flattened. Most who haven't come back by now won't. Either invest heavily (reactivation campaign with a meaningful offer) or accept the loss and stop spending.
## How this chapter complements the others
| Chapter | Question | Output |
|---|---|---|
| 04 — CLV (BG/NBD) | *Will this specific customer come back, and how much will they spend?* | Per-customer P(alive), expected purchases, 12-month CLV |
| 06 — Survival (this) | *When does a customer's return probability decay, and what speeds or slows it?* | Population & stratified survival curves, hazard ratios, intervention thresholds |
CLV is *forward-looking, individual, monetary*. Survival is *time-aware, population, operational*. Together they answer "**who** to spend on, and **when** to spend".
## Limitations
- **No effects in synthetic data**. The covariate analysis is honest but unexciting — by construction, no first-purchase feature drives the return timing here. With real data, hazard ratios on category, price tier, and discount usage would typically all be non-null.
- **Right-censoring is heavy.** 71% of the cohort is censored. The Kaplan-Meier estimator handles this correctly, but the precision of the tail of the curve degrades as fewer customers remain at risk.
- **First-to-second only.** We only modeled time-to-*first-repeat*. A natural extension is recurrent-event survival: looking at all inter-purchase gaps. `lifelines` supports this via `WeibullAFTFitter` with frailty terms; it's a follow-up worth doing if the data has enough repeat-buyers.